 +1 713 701 5957
+1 713 701 5957 +44 191 308 5117
+44 191 308 5117 +61 (2) 8003 7653
+61 (2) 8003 7653

Johnny-Five
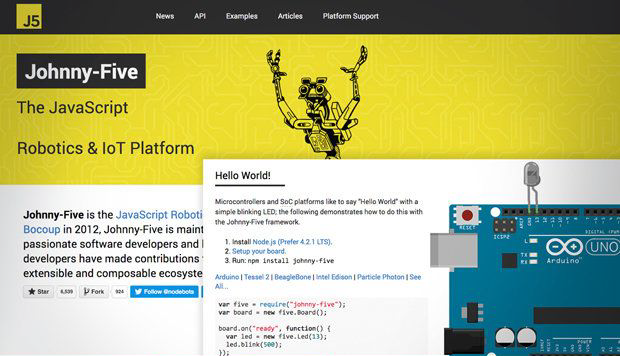
You might think the JavaScript language was a mismatch for robotics and IoT applications, but you’d be wrong. The movement to apply JavaScript to robotics has been growing since 2010. Yes, many production apps for micro controllers are written in C or Python, but asking a student learning robotics to master C programming first is making things way too hard.
The Johnny-Five framework wants to be a baseline control kit for hardware projects. It supports a bunch of single-board computers, including Arduino (all models), Electric Imp, BeagleBone, Intel Galileo and Edison, Linino One, Pinoccio, pcDuino3, Raspberry Pi, Particle/Spark Core and Photon, Tessel 2, and TI LaunchPad. Johnny-Five can support so many boards because it is based on the Firmata protocol and has an IO plug-in architecture.
Depending on the board, Johnny-Five may run in an on-board Linux environment, as well as on a host machine tethered to a client (via Serial USB or Ethernet), communicating over Wi-Fi to the client, or communicating over Bluetooth to the client. Running tethered isn’t a bad thing in a development environment; in production you might want to switch to a board with wireless or internal Linux support.
In Johnny-Five, the basic abstractions are hardware building blocks: boards, LEDs, servos, GPS, motors, relays, buttons, switches, sensors, and so on. Each class has pretty much the methods, properties, events, and collections you’d expect.
- Martin Heller
The Johnny-Five framework wants to be a baseline control kit for hardware projects. It supports a bunch of single-board computers, including Arduino (all models), Electric Imp, BeagleBone, Intel Galileo and Edison, Linino One, Pinoccio, pcDuino3, Raspberry Pi, Particle/Spark Core and Photon, Tessel 2, and TI LaunchPad. Johnny-Five can support so many boards because it is based on the Firmata protocol and has an IO plug-in architecture.
Depending on the board, Johnny-Five may run in an on-board Linux environment, as well as on a host machine tethered to a client (via Serial USB or Ethernet), communicating over Wi-Fi to the client, or communicating over Bluetooth to the client. Running tethered isn’t a bad thing in a development environment; in production you might want to switch to a board with wireless or internal Linux support.
In Johnny-Five, the basic abstractions are hardware building blocks: boards, LEDs, servos, GPS, motors, relays, buttons, switches, sensors, and so on. Each class has pretty much the methods, properties, events, and collections you’d expect.
- Martin Heller
Pandas
The Python language by itself is great for massaging data, but not so great for analysis and modeling. Enter Pandas, which provides high-performance, easy-to-use data structures and data analysis tools for the Python programming language. Pythonistas claim that Pandas combined with Jupyter notebooks, Scikit-learn (for machine learning), and Statsmodels (statistics and econometrics) makes it unnecessary for them to use R for data analysis and modeling.
The key features of Pandas include a fast and efficient R-like DataFrame object for data manipulation with integrated indexing; methods for reading and writing data between in-memory data structures and different formats; data alignment and handling of missing data; reshaping and pivoting of data sets; aggregating or transforming data with a SQL-like group by engine; merging and joining of data sets; hierarchical axis indexing; time series functionality; and optimized performance. Pandas requires NumPy and optionally SciPy, Matplotlib, and Statsmodels. Pandas is in turn a dependency of Statsmodels.
- Martin Heller
The key features of Pandas include a fast and efficient R-like DataFrame object for data manipulation with integrated indexing; methods for reading and writing data between in-memory data structures and different formats; data alignment and handling of missing data; reshaping and pivoting of data sets; aggregating or transforming data with a SQL-like group by engine; merging and joining of data sets; hierarchical axis indexing; time series functionality; and optimized performance. Pandas requires NumPy and optionally SciPy, Matplotlib, and Statsmodels. Pandas is in turn a dependency of Statsmodels.
- Martin Heller

Scikit-learn
Scikit-learn is one of the key components of a Python-based toolkit for data analysis, along with Pandas, Jupyter notebooks, Statsmodels, and its own dependencies NumPy, SciPy, and Matplotlib. The Scikit-learn Python module implements tools for machine learning, including algorithms for classification, clustering, regression, dimensionality reduction, feature extraction, model selection, and preprocessing. There are enough algorithms that Scikit-learn supplies a cheat sheet to point you in the correct direction.
The machine learning algorithm selection in Scikit-learn is limited to well-established options, meaning there have been at least three years since publication, with 200-plus citations, wide use, and demonstrated utility. There are many companion Python modules that handle tasks outside the scope of Scikit-learn: Seqlearn and Hmmlearn for hidden Markov models, PyStruct for structured predictions, Pandas and Statsmodels for statistics, Theano for deep learning, Scikit-image for image processing, and NLTK for natural language processing.
- Martin Heller
The machine learning algorithm selection in Scikit-learn is limited to well-established options, meaning there have been at least three years since publication, with 200-plus citations, wide use, and demonstrated utility. There are many companion Python modules that handle tasks outside the scope of Scikit-learn: Seqlearn and Hmmlearn for hidden Markov models, PyStruct for structured predictions, Pandas and Statsmodels for statistics, Theano for deep learning, Scikit-image for image processing, and NLTK for natural language processing.
- Martin Heller
Caffe
Caffe is a deep learning framework from the Berkeley Vision and Learning Center, released under the BSD 2-Clause license. The core Caffe framework is written in C++ with support for CUDA on Nvidia GPUs and the ability to switch between running on CPUs and GPUs. Caffe has command-line, Python (including Jupyter Notebook), and Matlab interfaces.
While Caffe was originally aimed at computer vision learning using neural networks, it has also been used for speech, image sequence, and multimedia recognition. Philosophically, it is designed to be an expressive, extensible, modular, high-speed framework supported by an active community.
As a deep learning framework, Caffe implements a number of different kinds of compute layers -- such as data, convolution, loss, reduction, and pooling -- connected into a directed acyclic graph (DAG) network. An assortment of solvers, such as stochastic gradient descent (STG), find the best parameters by forward inference and back-propagation, with automatic calculation of the gradients at each step. A “model zoo” is useful for sharing networks and solved weights. You can speed up your own work by adapting existing solved networks for different features and classifications.
Caffe installs on Docker, Ubuntu, OS X, RHEL, CentOS, Fedora, and Windows. An experimental branch of the Caffe repository implements an OpenCL back end as an alternative to CUDA.
Caffe is used at Facebook and Pinterest to recognize objects and flag objectionable content in uploaded images, at Adobe to catalog typefaces, and at Yahoo Japan to personalize news and content.
- Martin Heller
While Caffe was originally aimed at computer vision learning using neural networks, it has also been used for speech, image sequence, and multimedia recognition. Philosophically, it is designed to be an expressive, extensible, modular, high-speed framework supported by an active community.
As a deep learning framework, Caffe implements a number of different kinds of compute layers -- such as data, convolution, loss, reduction, and pooling -- connected into a directed acyclic graph (DAG) network. An assortment of solvers, such as stochastic gradient descent (STG), find the best parameters by forward inference and back-propagation, with automatic calculation of the gradients at each step. A “model zoo” is useful for sharing networks and solved weights. You can speed up your own work by adapting existing solved networks for different features and classifications.
Caffe installs on Docker, Ubuntu, OS X, RHEL, CentOS, Fedora, and Windows. An experimental branch of the Caffe repository implements an OpenCL back end as an alternative to CUDA.
Caffe is used at Facebook and Pinterest to recognize objects and flag objectionable content in uploaded images, at Adobe to catalog typefaces, and at Yahoo Japan to personalize news and content.
- Martin Heller

CNTK

CNTK, the Computational Network Toolkit from Microsoft Research, is a unified deep-learning toolkit that describes neural networks as a series of computational steps via a directed graph. Microsoft describes it as production-quality, open source, multimachine, multi-GPU, and highly efficient for neural network training to recognize and classify speech, images, and text. You can install CNTK on Windows or Linux, on Azure, or as a Docker container.
When CNTK was released in January, Microsoft’s own comparisons showed it to be faster than all of the competing neural network learning toolkits -- Theano, TensorFlow, Torch 7, and Caffe -- running on the same hardware. Microsoft also claimed it was the only one to scale multiple CUDA (Nvidia) GPUs across multiple machines. Since then, Google has revealed its Tensor Processing Unit, which may change the speed equation when Tensor Processing Unit services for TensorFlow are available to Google Cloud customers. Google also added distributed computing support to TensorFlow.
CNTK supports Feed Forward, CNN (convolutional neural networks), LSTM (long short-term memory), and RNN (recurrent neural networks), and a full suite of training algorithms. Unique to CNTK, a 1-bit SGD algorithm improves performance for deep neural network training, but has a more restrictive license than the rest of CNTK. A newer version of CNTK, planned for September 2016, will include Reinforcement Learning pipelines, as well as CNTK APIs supporting Python, C++, and .Net (C#) bindings.
- Martin Heller
When CNTK was released in January, Microsoft’s own comparisons showed it to be faster than all of the competing neural network learning toolkits -- Theano, TensorFlow, Torch 7, and Caffe -- running on the same hardware. Microsoft also claimed it was the only one to scale multiple CUDA (Nvidia) GPUs across multiple machines. Since then, Google has revealed its Tensor Processing Unit, which may change the speed equation when Tensor Processing Unit services for TensorFlow are available to Google Cloud customers. Google also added distributed computing support to TensorFlow.
CNTK supports Feed Forward, CNN (convolutional neural networks), LSTM (long short-term memory), and RNN (recurrent neural networks), and a full suite of training algorithms. Unique to CNTK, a 1-bit SGD algorithm improves performance for deep neural network training, but has a more restrictive license than the rest of CNTK. A newer version of CNTK, planned for September 2016, will include Reinforcement Learning pipelines, as well as CNTK APIs supporting Python, C++, and .Net (C#) bindings.
- Martin Heller
NLTK
NLTK, the Natural Language Toolkit, is a platform for building Python programs to work with human language data. It provides interfaces to more than 50 corpora and lexical resources such as WordNet, along with wrappers for natural language processing languages, and a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning.
NLTK originated at the University of Pennsylvania, and it is currently being used in courses at 32 universities worldwide. Highlights of NLTK include lexical analysis (that is, word and text tokenization); n-gram and collocations; part-of-speech tagging; a tree model and text chunker; and named-entity recognition.
NLTK is available for Windows, OS X, and Linux. There is an online book about NLTK, Natural Language Processing with Python. NLTK requires Python 2.7 or 3.2 or later.
- Martin Heller
NLTK originated at the University of Pennsylvania, and it is currently being used in courses at 32 universities worldwide. Highlights of NLTK include lexical analysis (that is, word and text tokenization); n-gram and collocations; part-of-speech tagging; a tree model and text chunker; and named-entity recognition.
NLTK is available for Windows, OS X, and Linux. There is an online book about NLTK, Natural Language Processing with Python. NLTK requires Python 2.7 or 3.2 or later.
- Martin Heller

TensorFlow

If there is a “magic sauce” at Google today, it is machine learning and deep neural networks. The machine learning package Google uses is TensorFlow, assisted by Tensor processing units (TPUs) in its datacenters. TensorFlow was developed by the Google Brain team over several years and released to open source in November 2015.
TensorFlow does computation using data flow graphs for scalable machine learning. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) that flow between them. This flexible architecture lets you deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device without rewriting code.
You can install TensorFlow on Ubuntu Linux and OS X, using Python 2.7, 3.4, or 3.5. Nvidia CUDA GPUs are supported on Linux. Google supplies Docker images for TensorFlow with and without GPU support.
The principal language for using TensorFlow is Python, and there is limited support for C++. The tutorials supplied with TensorFlow include applications for classification of handwritten digits, image recognition, word embeddings, recurrent neural networks, sequence-to-sequence models for machine translation, natural language processing, and PDE (partial differential equation)-based simulations.
The tensorflow/tensorflow repository on GitHub has more than 30,000 stars and almost 8,000 commits. According to Jeff Dean, leader of the Google Brain team, in February 2016 there were 1,500 repositories on GitHub that mentioned TensorFlow, five of which were from Google.
- Martin Heller
TensorFlow does computation using data flow graphs for scalable machine learning. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) that flow between them. This flexible architecture lets you deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device without rewriting code.
You can install TensorFlow on Ubuntu Linux and OS X, using Python 2.7, 3.4, or 3.5. Nvidia CUDA GPUs are supported on Linux. Google supplies Docker images for TensorFlow with and without GPU support.
The principal language for using TensorFlow is Python, and there is limited support for C++. The tutorials supplied with TensorFlow include applications for classification of handwritten digits, image recognition, word embeddings, recurrent neural networks, sequence-to-sequence models for machine translation, natural language processing, and PDE (partial differential equation)-based simulations.
The tensorflow/tensorflow repository on GitHub has more than 30,000 stars and almost 8,000 commits. According to Jeff Dean, leader of the Google Brain team, in February 2016 there were 1,500 repositories on GitHub that mentioned TensorFlow, five of which were from Google.
- Martin Heller
Theano
Theano is a Python library that lets you define, optimize, and evaluate mathematical expressions, especially ones with multidimensional arrays. It was developed at the LISA lab of the University of Montreal to support rapid development of efficient machine learning algorithms, and it has been used to support large-scale, computationally intensive scientific investigations since 2007. The University of Montreal uses Theano in its machine learning and deep learning classes.
Theano installs on Linux, MacOS, and Windows, and it can use Python 2 or Python 3. Theano is tightly integrated with NumPy. It can use a CUDA (Nvidia) GPU transparently if you install GPU support.
Theano combines aspects of a computer algebra system (CAS) with aspects of an optimizing compiler. It can generate custom C code for many mathematical operations, can perform symbolic differentiation (for computing gradients, which are key to many machine learning optimizers), and can recognize some numerically unstable expressions and compute them with more stable algorithms.
A number of related projects use Theano, including Lasagne, Blocks, Keras, and OpenDeep to do neural network training; DeepMedic to do brain lesion segmentation; and Theanet and Elektronn for image classification.
- Martin Heller
Theano installs on Linux, MacOS, and Windows, and it can use Python 2 or Python 3. Theano is tightly integrated with NumPy. It can use a CUDA (Nvidia) GPU transparently if you install GPU support.
Theano combines aspects of a computer algebra system (CAS) with aspects of an optimizing compiler. It can generate custom C code for many mathematical operations, can perform symbolic differentiation (for computing gradients, which are key to many machine learning optimizers), and can recognize some numerically unstable expressions and compute them with more stable algorithms.
A number of related projects use Theano, including Lasagne, Blocks, Keras, and OpenDeep to do neural network training; DeepMedic to do brain lesion segmentation; and Theanet and Elektronn for image classification.
- Martin Heller

TORCH

Torch computing framework with wide support for machine learning algorithms that puts GPUs first. It is easy to use and efficient, thanks to the LuaJIT scripting language and an underlying C/CUDA implementation. (There is also an OpenCL port.) Torch comes with a large ecosystem of community-created packages in machine learning, computer vision, signal processing, parallel processing, image and video processing, and networking among others, and it builds on top of the Lua community.
Spark
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.

Gensim

Gensim is a free Python library designed to automatically extract semantic topics from documents, as efficiently (computer-wise) and painlessly (human-wise) as possible.
Gensim is designed to process raw, unstructured digital texts (“plain text”). The algorithms in gensim, such as Latent Semantic Analysis, Latent Dirichlet Allocation and Random Projections discover semantic structure of documents by examining statistical co-occurrence patterns of the words.
Gensim is designed to process raw, unstructured digital texts (“plain text”). The algorithms in gensim, such as Latent Semantic Analysis, Latent Dirichlet Allocation and Random Projections discover semantic structure of documents by examining statistical co-occurrence patterns of the words.
Elastics
Elastic's open source solutions solve a growing list of search, log analysis, and analytics challenges across virtually every industry. Our commercial security and monitoring products take our open source stack further by broadening what's possible with your data.

Machine Learning Webpage on Pragmatic Website
Machine Learning can unlock valuable insights from your organization’s data and provide very interesting predictive Analytics to help make informed decisions.Machine Learning Our Approach
http://machinelearningmastery.com/process-for-working-through-machine-learning-problems/Our Systematic Approach For Working Through Machine Learning and Predictive Modeling Problems Delivers Above Average Results
1] Problem Definition
We use a three step process to define the problem in consultation with the client:- Step 1: What is the problem? We describe the problem informally and formally and list assumptions and similar problems
- Step 2: Why does the problem need to be solved? What is the motivation for solving the problem, the benefits a solution provides and how the solution will be used
- Step 3: How would We solve the problem? We describe how the problem would be solved manually to flush domain knowledge
2] Prepare Data
We preface data preparation with a data analysis phase that involves summarizing the attributes and visualizing them using scatter plots and histograms. We also like to describe in detail each attribute and relationships between attributes. This base work forces us to think about the data in the context of the problem before it is lost to the algorithmsThe actual data preparation process is three step as follows:
- Step 1: Data Selection: Consider what data is available, what data is missing and what data can be removed
- Step 2: Data Preprocessing: Organize your selected data by formatting, cleaning and sampling from it
- Step 3: Data Transformation: Transform preprocessed data ready for machine learning by engineering features using scaling, attribute decomposition and attribute aggregation
3] Identify Machine Learning Algorithms and Services
We work with Amazon Machine Learning(https://aws.amazon.com/machine-learning/)
and Google CLoud Machine Learning Service
(https://cloud.google.com/products/machine-learning/)
Also we have Python nased libraries which support various Algorithms. Based on the problem at hand one or many types of algorithm need to be selected. The training and final deployment of the model can be done on Premise server or on the cloud. The decision where to deploy depends on the problem at hand. Here is a summary of different types of Algorithms.
A] Regression Algorithms
Regression is concerned with modeling the relationship between variables that is iteratively refined using a measure of error in the predictions made by the model.- Ordinary Least Squares Regression (OLSR)
- Linear Regression
- Logistic Regression
- Stepwise Regression
- Multivariate Adaptive Regression Splines (MARS)
- Locally Estimated Scatterplot Smoothing (LOESS)
B] Instance-based Algorithms
Instance-based learning model is a decision problem with instances or examples of training data that are deemed important or required to the model.- k-Nearest Neighbor (kNN)
- Learning Vector Quantization (LVQ)
- Self-Organizing Map (SOM)
- Locally Weighted Learning (LWL)
C] Regularization Algorithms
An extension made to another method (typically regression methods) that penalizes models based on their complexity, favoring simpler models that are also better at generalizing.- Ridge Regression
- Least Absolute Shrinkage and Selection Operator (LASSO)
- Elastic Net
- Least-Angle Regression (LARS)
D] Decision Tree Algorithms
Decision tree methods construct a model of decisions made based on actual values of attributes in the data.- Classification and Regression Tree (CART)
- Iterative Dichotomiser 3 (ID3)
- C4.5 and C5.0 (different versions of a powerful approach)
- Chi-squared Automatic Interaction Detection (CHAID)
- Decision Stump
- M5
- Conditional Decision Trees
E] Bayesian Algorithms
Bayesian methods are those that explicitly apply Bayes’ Theorem for problems such as classification and regression.- Naive Bayes
- Gaussian Naive Bayes
- Multinomial Naive Bayes
- Averaged One-Dependence Estimators (AODE)
- Bayesian Belief Network (BBN)
- Bayesian Network (BN)
F] Clustering Algorithms
Clustering, like regression, describes the class of problem and the class of methods.- k-Means
- k-Medians
- Expectation Maximisation (EM)
- Hierarchical Clustering
G] Association Rule Learning Algorithms
Association rule learning methods extract rules that best explain observed relationships between variables in data.- Apriori algorithm
- Eclat algorithm
H] Artificial Neural Network Algorithms
Artificial Neural Networks are models that are inspired by the structure and/or function of biological neural networks- Perceptron
- Back-Propagation
- Hopfield Network
- Radial Basis Function Network (RBFN)
I] Deep Learning Algorithms
Deep Learning methods are a modern update to Artificial Neural Networks that exploit abundant cheap computation.- Deep Boltzmann Machine (DBM)
- Deep Belief Networks (DBN)
- Convolutional Neural Network (CNN)
- Stacked Auto-Encoders
J] Dimensionality Reduction Algorithms
Like clustering methods, dimensionality reduction seek and exploit the inherent structure in the data, but in this case in an unsupervised manner or order to summarize or describe data using less information.- Principal Component Analysis (PCA)
- Principal Component Regression (PCR)
- Partial Least Squares Regression (PLSR)
- Sammon Mapping
- Multidimensional Scaling (MDS)
- Projection Pursuit
- Linear Discriminant Analysis (LDA)
- Mixture Discriminant Analysis (MDA)
- Quadratic Discriminant Analysis (QDA)
- Flexible Discriminant Analysis (FDA)
K] Ensemble Algorithms
Ensemble methods are models composed of multiple weaker models that are independently trained and whose predictions are combined in some way to make the overall prediction.- Boosting
- Bootstrapped Aggregation (Bagging)
- AdaBoost
- Stacked Generalization (blending)
- Gradient Boosting Machines (GBM)
- Gradient Boosted Regression Trees (GBRT)
- Random Forest
L] Other Algorithms
- Support Vector Machines
- Computational intelligence (evolutionary algorithms, etc.)
- Computer Vision (CV)
- Natural Language Processing (NLP)
- Recommender Systems
- Reinforcement Learning
- Graphical Models
4] Evaluate the Shortlisted Algorithms
Once we have defined your problem and prepared our data you need to apply machine learning algorithms to the data in order to solve the problem. We recommend to shortlist at least 3 Algorithms depending on problem at hand and evaluate how they perform. More Algorithms can be selected if the output is not in order. Also if time is no huge constraint on time more Algorithms can be tested. Evaluation process consist of following steps.Step 1] Test Harness
We need to define a test harness. The test harness is the data we will train and test an algorithm against and the performance measure we will use to assess its performance. It is important to define the test harness well so that we can focus on evaluating different algorithms and thinking deeply about the problem.Step 2] Performance Measure
The performance measure is the way we want to evaluate a solution to the problem. It is the measurement we will make of the predictions made by a trained model on the test dataset.Performance measures are typically specialized to the class of problem you are working with, for example classification, regression, and clustering. Many standard performance measures will give you a score that is meaningful to your problem domain. For example, classification accuracy for classification (total correct correction divided by the total predictions made multiple by 100 to turn it into a percentage).
Step 3] Test and Train Datasets
From the transformed data, you will need to select a test set and a training set. An algorithm will be trained on the training dataset and will be evaluated against the test set. This may be as simple as selecting a random split of data (66% for training, 34% for testing) or may involve more complicated sampling methods.A trained model is not exposed to the test dataset during training and any predictions made on that dataset are designed to be indicative of the performance of the model in general. As such you want to make sure the selection of your datasets are representative of the problem you are solving.
Step 4] Cross Validation
A more sophisticated approach than using a test and train dataset is to use the entire transformed dataset to train and test a given algorithm. A method you could use in your test harness that does this is called cross validation.It first involves separating the dataset into a number of equally sized groups of instances (called folds). The model is then trained on all folds exception one that was left out and the prepared model is tested on that left out fold. The process is repeated so that each fold get’s an opportunity at being left out and acting as the test dataset. Finally, the performance measures are averaged across all folds to estimate the capability of the algorithm on the problem.